PPO
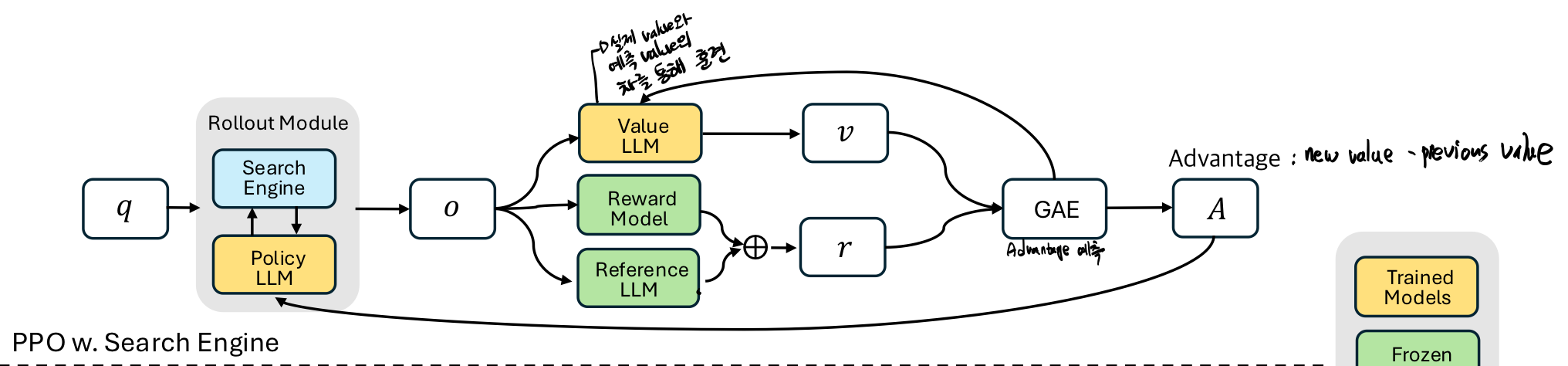
Search-R1에서의 PPO 예시 (search engine과 함께 이용)
잘 설명해준 블로그 ->
https://ai-com.tistory.com/entry/RL-강화학습-알고리즘-5-PPO
기본적으로 advantage를 극대화 하면서도, old policy에서 업데이트된 new policy가 너무 차이가 크지 않기 위해서 clipping을 사용 (절벽 가장자리를 걷는 것과 같은 비유로 설명할 수 있는데, 새로운 정책이 이전 정책으로부터 안전한 거리 내에서만 업데이트되도록 보장)